
Analysing complexity of parliamentary speech
Introduction
In this post I’ll walk through the steps of an analysis of parliamentary speech. I’ll be using data from ParlSpeechV2 to assess the complexity of how politicians talk in parliaments, as well as analyse predictors of the complexity of parliamentary speech. In this post I go through how to use ParlSpeech data, and how to merge it with other sources such as ParlGov and EveryPolitician. I will then go through how to evaluate the complexity a speech using text-as-data methods, some exploratory analysis and visualization, and some statistical inference.
Content
Data preparation
ParlSpeech data
To start of I’ll be using data from ParlSpeechV2, which is a dataset collected by Rauh and Schwalbach (2020). It contains parliamentary data from eight western countries, with a coverage of about 21-32 years depending on the country. To simplify matters we’ll only use the Swedish data this time, but this could be expanded from there to include data from the other countries. I first create a project directory for this project, and then download the data from this. I save it as Corp_Riksdagen_V2.rds in my project folder.
The data can then be loaded into the R session through
> Corp_Riksdagen_V2 <- readRDS("Corp_Riksdagen_V2.rds")
We start by just exploring what the data looks like and what it contain.
> str(Corp_Riksdagen_V2)
'data.frame': 365560 obs. of 11 variables:
$ date : chr "1990-10-02" "1990-10-02" "1990-10-16" "1990-10-16" ...
$ agenda : chr "Välkomstord" "Meddelande om kammarens arbete" "Svar på fråga 1990/91:44 om lagen om anställningsskydd" "Svar på fråga 1990/91:44 om lagen om anställningsskydd" ...
$ speechnumber : int 1 2 1 2 3 4 5 6 7 8 ...
$ speaker : chr "TALMANNEN" "TALMANNEN" "Arbetsmarknadsminister MONA SAHLIN" "LARS-OVE HAGBERG" ...
$ party : chr NA NA "S" "V" ...
$ party.facts.id: num NA NA 487 830 487 830 487 830 487 690 ...
$ chair : logi TRUE TRUE FALSE FALSE FALSE FALSE ...
$ terms : num 563 92 204 255 231 148 39 95 291 242 ...
$ text : chr "Ärade ledamöter! Jag hälsar er alla varmt välkomna tillbaka till riksdagen och till ett nytt arbetsår. Ett år s"| __truncated__ "Såsom framgår av utsänd sammanträdesplan anordnas i morgon partiledardebatt, som tar sin början kl. 10.00. På o"| __truncated__ "Herr talman! Lars-Ove Hagberg har frågat mig om regeringen är beredd att ändra i lagen om anställningsskydd så "| __truncated__ "Herr talman! När Borlänge kommun olyckligtvis var med och planerade ett affärscentrum uppstod problem. Butikern"| __truncated__ ...
$ parliament : chr "SW-Riksdagen" "SW-Riksdagen" "SW-Riksdagen" "SW-Riksdagen" ...
$ iso3country : chr "SWE" "SWE" "SWE" "SWE" ...
Clearly there are many variables we don’t need, and there seem to be speeches from actors in a non-partisan role such as the speaker of the house (Talmannen). To sort out the data we therefore use the tidyverse package to fix this. Here we select the variables of interest, and remove all rows from persons with no party affiliation.
library(tidyverse)
Corp_Riksdagen_V2 <- Corp_Riksdagen_V2 %>%
select(date,party,party.facts.id,speaker,text) %>%
filter(!is.na(party))
This is much better. However, the party variable is still treated as a character in reality we want to use it as a factor. To solve this we use
Corp_Riksdagen_V2$party <- factor(Corp_Riksdagen_V2$party)
To see what parties that exist in our data we can use the levels command.
> levels(Corp_Riksdagen_V2$party)
[1] "C" "FP" "KD" "L" "M" "MP" "NYD" "S" "SD" "V"
Those who are familiar with Swedish politics, will probably notice an issue here, namely that we have two distinct levels called “FP” and “L”. These in fact represent the same party which underwent a namechange from Folkpartiet to Liberalerna, in 2015. We would want these to be of the same level, and can therefore adjust this through:
levels(Corp_Riksdagen_V2$party) <- c("C","L","KD","L","M","MP","NYD","S","SD","V")
Last thing before moving on is to create an identifier of each post, I often do this to keep track of my data. To do this I create a new id variable with a unique number for each speech.
Corp_Riksdagen_V2$id <- 1:nrow(Corp_Riksdagen_V2)
Merging with EveryPolitician and ParlGov
Now we have our data in order, but before moving on to analyzing the parliamentary speech there are a number of variables I would like to add, namely the gender and age of each politician, and the government status of each party for each date. To get the gender and age of each politician I will try to use data from EveryPolitician (the project is currently paused and does not have a 100% coverage, but will make do for this small project). To make everything convenient there is an R package available for accessing their data.
library(devtools)
install_github("ajparsons/everypoliticianR")
library(everypoliticianR)
Now to get the data from Sweden we can run
sweden <- everypolitician("Sweden")
sweden <- sweden$persons
This code access their entire database of Sweden, and then extracts the data on every individual politician in the data. In their data there are two variables of interest, namely gender and birthyear (which we can use to get age), and we want to merge this data with our ParlSpeech data. Unfortunately there is no ID key linked with each politician such that we can match them perfectly. Therefore I’ll try to match every politician with their full name. This is not unproblematic, as some politicians have the same name. However, most often those who share the same name will also have the same gender so that is not an issue. For age, this might be more problems but I will ignore that. Another issue that can emerge in this approach is that politicians change name, there might be misspellings and different structures, which makes matching on the name imperfect, this I will also just ignore. Before matching is possible, I will have to do some minimal preprocessing, to do this I use the stringr package.
The names in the EveryPolitician is fairly cleaned so I will just make all names lowercase.
> sweden$name <- tolower(sweden$name)
> head(sweden$name)
[1] "björn rosengren" "lisbeth grönfeldt bergman" "anita bråkenhielm"
[4] "erik ezelius" "karin israelsson" "osama ali maher"
For the ParlSpeech data there is more work to be done.
> head(Corp_Riksdagen_V2$speaker)
[1] "Arbetsmarknadsminister MONA SAHLIN" "LARS-OVE HAGBERG"
[3] "Arbetsmarknadsminister MONA SAHLIN" "LARS-OVE HAGBERG"
[5] "Arbetsmarknadsminister MONA SAHLIN" "LARS-OVE HAGBERG"
Other than these examples some names are written as “MARIANNE ANDERSSON i Vårgårda”". In all these different strings we want to extract only the name. To do this I use str_replace to remove all words in each string which contain any word starting with a uppercase letter and then lowercase letters, I also remove all words containing of only lowercase letters After this I remove all excess spaces and turn the name fully to lowercase.
> Corp_Riksdagen_V2$name <- str_replace_all(Corp_Riksdagen_V2$speaker, "[A-ZÅÄÖ][a-zåäö-]+|[a-zåäö]+", "")
> Corp_Riksdagen_V2$name <- str_trim(Corp_Riksdagen_V2$name,side="both")
> Corp_Riksdagen_V2$name <- tolower(Corp_Riksdagen_V2$name)
> head(Corp_Riksdagen_V2$name)
[1] "mona sahlin" "lars-ove hagberg" "mona sahlin" "lars-ove hagberg" "mona sahlin"
[6] "lars-ove hagberg"
Now we have our data in order and should be able and merge it with the new data from EveryPolitician. To do this I use the merge command. In it I first write the main dataframe, and then the dataframe I want to add on. Given that there are only two variables we want to add on from the sweden dataframe, I only use those columns in the merge command. The by argument specifies which column we are merging by, and all.x=T specifies that we are keeping all rows in the first dataframe, even if there is no match with the second dataframe.
Corp_Riksdagen_V2 <- merge(Corp_Riksdagen_V2,sweden[c("birth_date","gender","name")],by="name",all.x = T)
So, how did the matching work? The attentive person will note that the new resulting dataframe contains more rows than the original dataframe, why is that? It is because some rows in Corp_Riksdagen_V2 matched with many rows in the sweden dataframe, this is because some politicians have the same name. To count the number of times this happened we can use the duplicated command. Furthermore, to see how many politicians did not find a match we can count the number of rows that are na in the gender column.
> sum(duplicated(Corp_Riksdagen_V2$ID))
[1] 7536
> sum(is.na(Corp_Riksdagen_V2$gender))
[1] 18318
There are clearly some problems with the match. Mostly the missing values seem to originate from lack of coverage rather than misspellings, although few examples of this likely occur. In a real study I would likely devote more time to solving these matching issues and do an error analysis of the mismatches, but for now we’ll just remove all missing values, and for all duplications we’ll just use one of the matches.
Corp_Riksdagen_V2 <- Corp_Riksdagen_V2 %>%
group_by(ID) %>%
filter(row_number() == 1) %>%
ungroup() %>%
filter(!is.na(gender))
Now there is just one variable missing, which is government status of each party. We could likely do this manually, but in order to be able and extend the analysis to more countries later it is good if we find a systematic way of doing this. For this project I’ll use the ParlGov data set, which is available here. After I’ve downloaded the cabinets data set and stored it as “parl_gov.csv” in the project folder, it can be accessed through
parl_gov <- read.csv("parl_gov.csv")
As can be seen it contains information about the government status for a lot of parties, in a lot of countries, for many elections. To reduce the data for the information we’ll need I do the following
parl_gov <- parl_gov[parl_gov$country_name_short=="SWE",]
parl_gov$start_date <- as.Date(parl_gov$start_date)
parl_gov <- parl_gov[parl_gov$start_date>as.Date("1985-01-01"),]
parl_gov <- parl_gov[c("party_id","start_date","cabinet_party","party_name")]
Now the data looks like this:
> head(parl_gov)
party_id start_date cabinet_party party_name
12350 1461 1985-09-15 0 Centerpartiet
12351 892 1985-09-15 0 Folkpartiet
12352 282 1985-09-15 0 Kristdemokraterna
12353 657 1985-09-15 0 Moderaterna
12354 904 1985-09-15 1 Socialdemokraterna
12355 882 1985-09-15 0 Vänsterpartiet (kommunisterna)
and the key issue now becomes, how can we use this data to create a government variable in our main data set? There are likely many better solutions to this, but what I, and ChatGPT, came up with after a lengthy discussion was to first create a new variable called end_date, which is the end_date of each government formed. The idea is that we can then see if a speach is made between these dates in order to then match it with a party and its corresponding value of the cabinet_party column. To do this we then write
parl_gov <- parl_gov %>%
arrange(party_id, start_date) %>%
group_by(party_id) %>%
mutate(end_date = lead(start_date, order_by = start_date, default = as.Date("2100-01-01"))) %>%
ungroup()
Now we are almost there, but how can we match this data on a party level with the other data? We have party_name and something called party_id. While we could likely do this by simply adjusting the party_name variable manually, I want a systematic way of doing this. Luckily, there exist such a way. The Party Facts project is an iniative that links together different datasets on political parties, and their dataset can be downloaded here. Thus I download the data called “external parties” and store it in my project folder.
partyfacts <- read_csv("partyfacts-mapping.csv")
When looking at the data we can see that it contains information on several countries and datasets. To make things easier we thus select all data on Sweden and parl_gov.
partyfacts <- partyfacts %>%
filter(!is.na(partyfacts_id)&country=="SWE"&dataset_key=="parlgov")
In the data there are two variables that we are interested in. The first one is dataset_party_id which is the id number used in parlgov for each party. The other one is the partyfacts_id which is the “master i” which party facts uses to link different datasets together. This id is infact the one which is given in the ParlSpeech data, and is currently called party.facts.id.
We can now use merge this data with the parl_gov data to get a party id we can use
parl_gov <- merge(parl_gov,partyfacts[c("dataset_party_id","partyfacts_id")],
by.x="party_id",by.y="dataset_party_id",all.x=T)
Now finally, we can use this data to get the government status of each speech in the ParlSpeech dataframe. To do this we can write
Corp_Riksdagen_V2 <- merge(Corp_Riksdagen_V2,parl_gov,by.x="party.facts.id",by.y="partyfacts_id") %>%
mutate(is_within_date = date > start_date & date <= end_date,
government = ifelse(is_within_date, cabinet_party, NA)) %>%
select(-start_date, -end_date, -cabinet_party, -is_within_date) %>%
arrange(date, party.facts.id) %>%
filter(!is.na(government))
This could is not beautiful, but it works… What I do is that I first merge the parl_gov and Corp_Riksdagen_V2 dataframes by the now joint party id. This becomes a very large dataframe given that for each individual speech there is a a match with all rows in the parl_gov dataframe containing that party id. Then, for each speech I check during which government period the speech was made, and create a new variable called government which takes the value of the cabinet_party variable in that period, for all other government periods this variable becomes NA. When this is done I remove the variables I don’t need, and remove all rows in which the government variable is NA. If done correctly, it should only be NA for all the excess rows where added in the initial merge. (This worked almost perfectly, only one row got accidentally excluded due to a specific case I’ll ignore in this case.)
Now we are almost done with all data preparation. The only last things I’ll do is to create a year variable containing the year a speech was made. I will do this by extracting the four first characters in the date column, which works given that the dates are in the format “YYYY-MM-DD”. In the same way I’ll create a birth year variable out of the birth_date variable, with these I’ll compute the age of the speaker for each speech. Finally I’ll make the gender and government variables into factors. This is all summarized in the following steps.
Corp_Riksdagen_V2$year <- as.numeric(substr(Corp_Riksdagen_V2$date,1,4))
Corp_Riksdagen_V2$birth_year <- as.numeric(substr(Corp_Riksdagen_V2$birth_date,1,4))
Corp_Riksdagen_V2$age <- Corp_Riksdagen_V2$year-Corp_Riksdagen_V2$birth_year
Corp_Riksdagen_V2$government <- factor(Corp_Riksdagen_V2$government)
Corp_Riksdagen_V2$gender <- factor(Corp_Riksdagen_V2$gender)
Evaluating the Complexity of Language
Now to the task of evaluating how complex a speech is. One popular method which have developed for Swedish texts is the LIX score, which stands for Läsbarhetsindex. It was developed in the 1960s by a Swedish scholar, and boils down to a very concise formula:
$$ LIX = \frac{W}{S}+\frac{L\times 100}{O} $$
In this text $W$ equals the number of words in the text, $S$ the number of sentences, and $L$ the number of long words, that is words longer than 6 characters. It is hard to get a valid measure language complexity across languages (Schoonvelde et al. 2019), but for now this will do, it is fairly well used in Swedish. Now, to compute the LIX score for all speeches I first create a function that computes the LIX score, and then apply it to every speech in the data.
calculate_lix <- function(text) {
sentences <- unlist(strsplit(text, "[.!?]"))
words <- unlist(strsplit(text, "\\W+"))
avg_sentence_length <- length(words) / length(sentences)
long_words <- sum(nchar(words) > 6)
proportion_long_words <- long_words / length(words)
lix <- avg_sentence_length + (proportion_long_words * 100)
return(lix)
}
Corp_Riksdagen_V2$lix <- sapply(Corp_Riksdagen_V2$text, calculate_lix)
Exploratory analysis
Now with the LIX scores calculated, and all the datasets merged, we can finally explore what the data looks like. First I’ll just use the summary function in R.
> summary(Corp_Riksdagen_V2$lix)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.50 34.58 38.44 38.72 42.64 181.63
The mean LIX score is 38, and most speeches score between 34 and 42, but there are some extreme outliers. To assess this further I’ll use a histogram.
ggplot(Corp_Riksdagen_V2,aes(lix))+
geom_histogram(col="black",stat="bin")+
xlab("LIX score")+
ylab("Count")+
theme_bw()
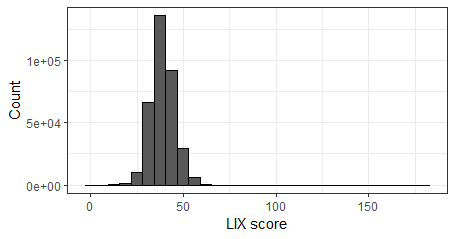
So what does the extremes mean hear? What is a complicated and not complicated speech? In my mind this analysis would require additional validation to make sure that we actually measure what we intend to measure here, but to get some understanding of this I look at the most simple and most complicated speech in the data.
> Corp_Riksdagen_V2[which.min(Corp_Riksdagen_V2$lix),]$text
[1] "Herr talman! Ja."
> Corp_Riksdagen_V2[which.max(Corp_Riksdagen_V2$lix),]$text
[1] "Fru Talman! Valberedningen har enhälligt godkänt gemensamma listor för valen av ledamöter och suppleanter i utskotten. I egenskap av ordförande i valberedningen ber jag att till talmannen få överlämna de gemensamma listorna. Företogs val av 17 ledamöter i utskotten. De av Sven Hulterström för dessa val avlämnade gemensamma listorna godkändes av kammaren, varvid följande personer, vilkas namn i här angiven ordning upptagits på respektive listor, befanns valda för återstoden av riksdagens innevarande valperiod till ledamöter i konstitutionsutskottet Kurt Ove Johansson Catarina Rönnung Anders Björck Axel Andersson Widar Andersson Birger Hagård Barbro Hietala Nordlund Birgitta Hambraeus Pär-Axel Sahlberg Jerry Martinger Birgit Friggebo Mats Berglind Kenneth Kvist Nikos Papadopoulos Inger René Peter Eriksson Håkan Holmberg finansutskottet Jan Bergqvist Sören Lekberg Lars Tobisson Lisbet Calner Bo Nilsson Sonja Rembo Arne Kjörnsberg Per-Ola Eriksson Sonia Karlsson Lennart Hedquist Anne Wibble Susanne Eberstein Johan Lönnroth Kristina Nordström Fredrik Reinfeldt Roy Ottosson Mats Odell skatteutskottet Lars Hedfors Anita Johansson Bo Lundgren Sverre Palm Karl Hagström Karl-Gösta Svenson Lisbeth Staaf-Igelström Rolf Kenneryd Björn Ericson Carl Fredrik Graf Isa Halvarsson Inger Lundberg Per Rosengren Ulla Rudin Jan-Olof Franzén Ronny Korsberg Holger Gustafsson justitieutskottet Lars-Erik Lövdén Birthe Sörestedt Gun Hellsvik Göran Magnusson Sigrid Bolkéus Göthe Knutson Märta Johansson Ingbritt Irhammar Margareta Sandgren Anders G Högmark Siw Persson Ann-Marie Fagerström Alice Åström Pär Nuder Maud Ekendahl Kia Andreasson Rolf Åbjörnsson lagutskottet Anita Persson Bengt Kronblad Rolf Dahlberg Carin Lundberg Rune Berglund Stig Rindborg Karin Olsson Agne Hansson Eva Arvidsson Henrik S Järrel Bengt Harding Olson Inger Segelström Tanja Linderborg Anders Ygeman Tomas Högström Yvonne Ruwaida Birgitta Carlsson utrikesutskottet Viola Furubjelke Inga-Britt Johansson Göran Lennmarker Nils T Svensson Berndt Ekholm Inger Koch Urban Ahlin Helena Nilsson Carina Hägg Bertil Persson Karl-Göran Biörsmark Tone Tingsgård Eva Zetterberg Agneta Brendt Lars Hjertén Bodil Francke Ohlsson Ingrid Näslund försvarsutskottet Britt Bohlin Iréne Vestlund Arne Andersson Christer Skoog Sven Lundberg Henrik Landerholm Karin Wegestål Anders Svärd Ola Rask My Persson Lennart Rohdin Birgitta Gidblom Jan Jennehag Håkan Juholt Olle Lindström Annika Nordgren Åke Carnerö socialförsäkringsutskottet Börje Nilsson Margareta Israelsson Gullan Lindblad Maud Björnemalm Anita Jönsson Margit Gennser Lennart Klockare Ingrid Skeppstedt Sven-Åke Nygårds Gustaf von Essen Sigge Godin Ronny Olander Ulla Hoffmann Mona Berglund Nilsson Ulf Kristersson Ragnhild Pohanka Rose-Marie Frebran socialutskottet Ingrid Andersson Rinaldo Karlsson Sten Svensson Hans Karlsson Christina Pettersson Liselotte Wågö Marianne Jönsson Roland Larsson Conny Öhman Leif Carlson Barbro Westerholm Mariann Ytterberg Stig Sandström Christin Nilsson Birgitta Wichne Thomas Julin Chatrine Pålsson kulturutskottet Åke Gustavsson Berit Oscarsson Elisabeth Fleetwood Anders Nilsson Leo Persson Stig Bertilsson Björn Kaaling Marianne Andersson Monica Widnemark Lennart Fridén Carl-Johan Wilson Agneta Ringman Charlotta L Bjälkebring Annika Nilsson Jan Backman Ewa Larsson Fanny Rizell utbildningsutskottet Björkman Jan Silfverstrand Bengt Ask Beatrice Johansson Eva Wärnersson Ingegerd Rydén Rune Lundberg Agneta Carlgren Andreas Danielsson Torgny Melin Ulf Edgren Margitta Eneroth Tomas Danestig-Olofsson Britt-Marie Westerlund Panke Majléne Hjortzberg-Nordlund Hans Goude Gunnar Davidson Inger trafikutskottet Monica Öhman Håkan Strömberg Per Westerberg Jarl Lander Per Erik Granström Tom Heyman Krister Örnfjäder Karin Starrin Hans Stenberg Birgitta Wistrand Kenth Skårvik Monica Green Karl-Erik Persson Lena Sandlin Lars Björkman Elisa Abascal Reyes Christina Axelsson jordbruksutskottet Sinikka Bohlin Inge Carlsson Göte Jonsson Kaj Larsson Leif Marklund Ingvar Eriksson Alf Eriksson Lennart Daléus Ingemar Josefsson Carl G Nilsson Eva Eriksson Ann-Kristine Johansson Maggi Mikaelsson Åsa Stenberg Eva Björne Gudrun Lindvall Lennart Brunander näringsutskottet Birgitta Johansson Bo Finnkvist Karin Falkmer Reynoldh Furustrand Mats Lindberg Mikael Odenberg Sylvia Lindgren Kjell Ericsson Barbro Andersson Chris Heister Christer Eirefelt Marie Granlund Lennart Beijer Dag Ericson Ola Karlsson Eva Goës Göran Hägglund arbetsmarknadsutskottet Johnny Ahlqvist Sten Östlund Per Unckel Berit Andnor Ingvar Johnsson Kent Olsson Martin Nilsson Elving Andersson Laila Bjurling Patrik Norinder Elver Jonsson Sonja Fransson Hans Andersson Kristina Zakrisson Christel Anderberg Barbro Johansson Dan Ericsson bostadsutskottet Lennart Nilsson Rune Evensson Knut Billing Bengt-Ola Ryttar Britta Sundin Sten Andersson Marianne Carlström Rigmor Ahlstedt Lars Stjernkvist Stig Grauers Erling Bager Lena Larsson Owe Hellberg Lilian Virgin Inga Berggren Per Lager Ulf Björklund"
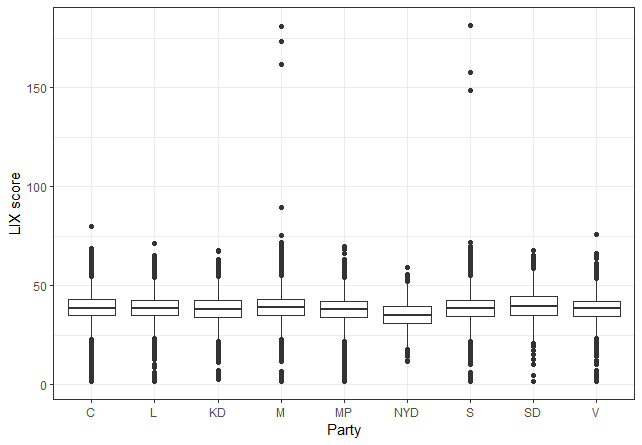
To explore party differences I use a boxplot to show how the LIX score varies between parties.
ggplot(Corp_Riksdagen_V2,aes(x=party,y=lix))+
geom_boxplot()+
theme_bw()+
xlab("Party")+
ylab("LIX score")
Statistical analysis
To explore these variations systematically I estimate a number of regression models, predicting the LIX score of a speech. First we’ll look at gender and age. Does it significantly impact how complex politicians talk?
m1 <- lm(lix~gender+age,data=Corp_Riksdagen_V2)
m2 <- lm(lix~gender+age+year,data=Corp_Riksdagen_V2)
stargazer(m1,m2,type="text")
| Dependent variable: | ||
| lix | ||
| (1) | (2) | |
| gendermale | 0.705*** | 0.670*** |
| (0.022) | (0.022) | |
| age | -0.058*** | -0.054*** |
| (0.001) | (0.001) | |
| Constant | 41.154*** | 42.213*** |
| (0.056) | (0.115) | |
| Year FE | No | Yes |
| Observations | 342,510 | 342,510 |
| R2 | 0.011 | 0.017 |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | |
Indeed it seems like male politicians talk significantly more complicated, and that older politician speak less complicated. Next, I’ll look at party and government status. Do politicians from different parties talk more or less complicated? And how do politicians talk when they are in government?
m3 <- lm(lix~government+year,data=Corp_Riksdagen_V2)
m4 <- lm(lix~party+year,data=Corp_Riksdagen_V2)
m5 <- lm(lix~government+party+year,data=Corp_Riksdagen_V2)
stargazer(m3,m4,m5,type="text")
| Dependent variable: | |||
| lix | |||
| (1) | (2) | (3) | |
| government1 | 0.839*** | 0.824*** | |
| (0.022) | (0.025) | ||
| partyL | -0.209*** | -0.180*** | |
| (0.049) | (0.049) | ||
| partyKD | -0.457*** | -0.425*** | |
| (0.051) | (0.051) | ||
| partyM | 0.257*** | 0.247*** | |
| (0.043) | (0.043) | ||
| partyMP | -0.982*** | -0.769*** | |
| (0.052) | (0.053) | ||
| partyNYD | -4.167*** | -3.703*** | |
| (0.126) | (0.126) | ||
| partyS | -0.206*** | -0.400*** | |
| (0.041) | (0.041) | ||
| partySD | 0.230*** | 0.634*** | |
| (0.085) | (0.086) | ||
| partyV | -0.471*** | -0.107** | |
| (0.120) | (0.120) | (0.120) | |
| Constant | 39.564*** | 40.087*** | 39.800*** |
| (0.100) | (0.105) | (0.105) | |
| Year FE | Yes | Yes | Yes |
| Observations | 342,510 | 342,510 | 342,510 |
| R2 | 0.012 | 0.014 | 0.017 |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | ||
In the first model I have only looked at the government variable with year fixed effects, here the results show that politicians in government talk more complicated. However, it could be that some parties talk more complicated in general, and that this affects who gets into government. Therefore in the second model I first look at party effects alone. In this model the Centre party is represented by the intercept, and all other party effects are how they differ from the Centre party. Here we see for example that the Moderate party and the Sweden Democrats are the only parties that talk more complicated, than the Centreparty. Where as all other parties, and especially Ny Demokrati, talk less complicated. In the third model I again look at the effect of government while controlling for year and party, meaning that I look how parties change their rhetoric as they enter, and leave, government. The effect is still positive, which indicates that parties change as they go into government.
The last thing I’ll do is to look at all variables at the same time, and present the results in a coefficient plot. While tables like these are nice, sometime it can be useful to use a Coefficient plot instead.
m6 <- lm(lix~government+party+gender+age+year,data=Corp_Riksdagen_V2)
coefs <- tidy(m6)
coefs <- coefs[!grepl("year|Intercept",coefs$term),]
ggplot(coefs,aes(x=term,y=estimate))+
geom_point()+
geom_errorbar(aes(ymin=estimate-1.96*std.error,ymax=estimate+1.96*std.error))+
theme_bw()+
coord_flip()+
geom_hline(yintercept=0,col="red",lty="dashed")+
xlab("Estimate")+
ylab("Coefficient")
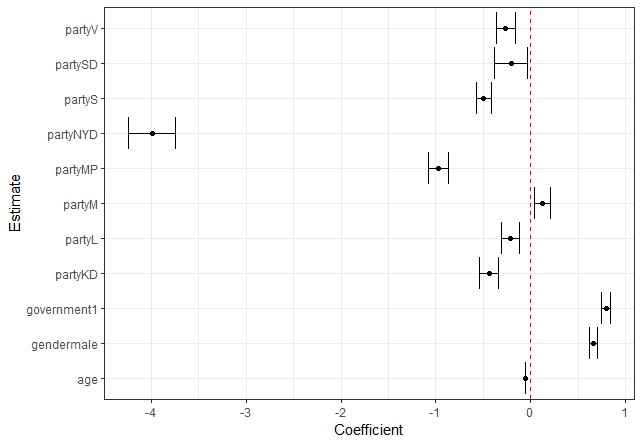
This plot summarizes most of the previous findings. For example parties talk more complicated in government, and male politicians talk more complicated. One interesting finding now however is that in the previous models SD was estimated to talk more complicated than other parties, but now they have a negative effect - why is that? Probably it is because SD is a male dominated party, and now when we control for gender, thus we compare males to males and females to females, within each party, every year, it seems like politicians from SD talk slightly less complicated than the Centre party which represent the intercept in this model. However, they still talk more complicated than politicians from S and KD.
Summary
In this post I have merged parliamentary speech data from ParlSpeech, merged it with data from EveryPolitician and ParlGov. I have then computed complexity of every speech through the LIX score and done some analysis on the results. Note that there is more to be done for these findings to be conclusive, for example analyzing coverage and validating the LIX measure. Nevertheless, I have gone through some of the most central steps in how I would approach this analysis.